At our last meeting, I gave a demo of how to make websites about what you're up to in data science. My demo followed the method used by astrophysicist and data scientist extraordinaire Jake Vanderplas. As he describes in a blog post, he now generates his site with the Python library Pelican. I'll walk you through his approach step-by-step below.
Another nice feature of Jake's approach is that it lets you avoid the hassle of buying and setting up a space on the web, by taking advantage of Github Pages. Github provides this space to host sites to developers for free. Many people in the data science and open source software community make Github Pages route: nuclear physicist Katy Huff, bioinformaticist Nelle Varoquaux, neuroscientist Cyrille Rosant, our own Eva Dyer at Georgia Tech, and even, uh, me (shameless plug, sorry). To be meta, I am now writing a blog post about my demo of how to make a blog. And to be even more meta, I made a website for our group by following my own demo. This blog post includes, as a bonus, stuff I remembered and/or figured out as I went through the process of setting up this site.
High-level overview
Here's a high-level overview of how this will work, in list form.
- follow instructions for set up
- write your posts
- follow instructions to update after you write post
- tweet out your blog posts and hope someone reads them
- repeat steps 2 through 4 as needed
- ...
- become a famous data scientist (sexiest job, 2014-present)
- publish a book and / or start a podcast, e.g. "Make Your Own Data Science Playing Cards From Scratch"
Some of the items in the list are more tongue-in-cheek then others.
Instructions for set up
Apparently I like lists. Here's another! I'll give detail for each step below. Note again that my instructions here are based on the Jake Vanderplas approach, as he outlines in this blog post and in the README for the source code for his blog, which he has helpfully made public in a Github repository. (For a slightly different approach, check out this walkthrough by Cyrille Rossant.)
1. make sure you have git installed for version control, and so you can take advantage of Github Pages
2. make a virtual environment for the software libraries you'll use to blog
- pelican: a static website generator written in Python
- jupyter to create notebooks
- ghp-import: a script that lets you use Github Pages to host your site by doing all the work for you
- some other tools that make it easy to use pelican and jupyter (Markdown, pelican-plugins)
3. set up a folder that will contain your blog, and initialize a git repository inside it
4. use pelican-quickstart command to quickly start a project (your blog)
(None of the items in that list were tongue-in-cheek.)
Okay, let's walk through each step in more detail.
1. make sure you have git installed (using conda) for version control, and to work with a Github account so you can take advantage of Github pages
In a shell, type:
$ conda install git
(Note that on Windows, instead of using terminal you'd use cmd.exe and the prompt would look like this: > conda install git. It's the same thing, I promise.)
There's many ways you can install git. Here I'm showing how you could do it with conda.
conda is a command-line tool that can install libraries in multiple languages and manage virtual environments (more on what that means in a second). It's provided as part of the Anaconda platform for scientific computing, which I highly recommend you use if you do anything (data) sciencey. (Link to download in the "helpful links" section.)
2. make an environment (using conda) ...
$ conda create -n pelican-blog python=3.6 jupyter notebook
$ source activate pelican-blog
It's good practice to isolate the libraries you use for any coding project in a virtual environment. This helps reproducibility (because you know exactly which libraries the code depends on) and helps you avoid "dependency hell". I won't go into detail about dependencies or virtual environments here, but a good example is in "helpful links".
2. ... and install the software libraries you'll use (with pip)
(pelican-blog) $ pip install pelican Markdown ghp-import
3. create a directory that will contain your blog, and initialize a git repository inside it
(pelican-blog) $ mkdir your-blog
(pelican-blog) $ cd your-blog
(pelican-blog) $ git init
Below are a couple more steps you need to execute inside the directory after you create it, although they fall under the category of "install the software libraries you'll use"
(pelican-blog) $ git submodule add https://github.com/danielfrg/pelican-ipynb
(pelican-blog) $ git submodule add https://github.com/getpelican/pelican-plugins
What you're doing here is some git voodoo that, as I understand it, makes these plugins part of your repository, but in such a way that you could still pull from them if their maintainers made some changes to the code.
Recent versions of git should get the actual code from these repos off Github and put it inside your local copy. But you might need to update your submodules, for example if you copy your own blog's repo off your Github profile onto another computer besides the one where you started the repo. In that case git doesn't pull in the code automatically so you need to execute:
git submodule update --init --recursive
4. use pelican-quickstart command to quickly start a project (your blog)
(pelican-blog) $ pelican-quickstart
Pelican will ask you a series questions about your site. You can safely accept all the defaults by just hitting enter--everything in this tutorial should work with those defaults.
write your posts
I like to write in Markdown, which looks like this:
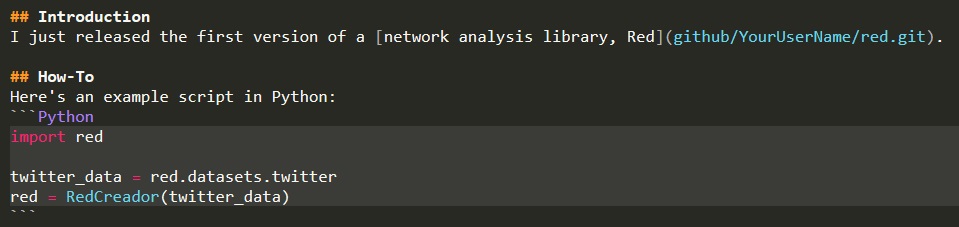
To be totally precise, I like to write in syntax that can be parsed by the Markdown library, which converts text to the html understood by web browsers. (You can read more about Markdown in "helpful links"). Hardcore Pythonistas using Pelican also have the option of writing in RestructuredText, a language created for Python docs.
To preview what you've written, you can do the following:
1. use pelican to convert your Markdown post into html that browsers know how to read
(pelican-blog) $ pelican content -o output -s pelicanconf.py
In the line above, you call pelican and tell it to run on the folder content. The flag -o (for 'output') tells Pelican what directory to put the output in (here named output), and the flag -s (for 'settings') tells Pelican which file contains the settings (in this case the pelicanconf.py file--the conf is for 'configuration').
After you execute that command in the terminal, Pelican will tell you something like:
Done: Processed 1 article, 0 drafts, 0 pages and 0 hidden pages in 1.94 seconds.
Ok, cool.
So what's your blog gonna look like on the web?
Handily, Python comes with a bare-bones server built in so you can check it out yourself.
2. Use the built-in Python server to serve your blog locally (just on your machine): Run the following in the terminal:
(pelican-blog) $ cd output
(pelican-blog) $ python -m http.server
It will spin up the server, which you will know because the terminal will give you a bunch of talkback like so:
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /quick-and-easy-data-science-websites.html HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/css/bootstrap.spacelab.min.css HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/css/pygments/native.css HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/css/font-awesome.min.css HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/css/style.css HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/js/jquery.min.js HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/js/bootstrap.min.js HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/js/respond.min.js HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /theme/js/bodypadding.js HTTP/1.1" 200 -
127.0.0.1 - - [29/Jun/2018 10:11:24] "GET /images/avatar.jpg HTTP/1.1" 200 -
Once the server is up in running, open your browser, and in the address bar enter: localhost:8000
where 8000 is the default port to which the Python server routes your site.
You should be able to navigate through your site.
Instructions to update after you write your post
So you'll iterate through through those two steps a few times until you get your site and post how you want them. Now how do you actually get it on the web?
1. use pelican again to output the final version of your site
(pelican-blog) $ pelican content -o output -s pelicanconf.py
2. use ghp-import to publish your Pelican site on Github, as either a Project Page or a User Page
(this code snippet stolen from the Pelican docs).
(pelican-blog) $ ghp-import output
(pelican-blog) $ git push origin gh-pages
For a User Page, you need to "push" the content from the output directory to the master branch of a repository named Username.github.io. So you should make one on Github, replacing Username with your actual Github user name. Github automagically converts a repository with the name formatted that way into a website. Step-by-step instructions for this on the command line are below.
But first, note that this means you need a separate repository for your source code!
For example we have the source code for the group's blog in:
https://github.com/Data-Science-for-Scientists-ATL/DataSci4ScienceATL-blog-source
And the "output" gets pushed to a different repository:
https://github.com/Data-Science-for-Scientists-ATL/Data-Science-for-Scientists-ATL.github.io
so once you have set up the separate repository for your User Page, you'd push to it like so:
(pelican-blog) $ pelican content -o output -s pelicanconf.py
(pelican-blog) $ ghp-import output
(pelican-blog) $ git push https://github.com/Data-Science-for-Scientists-ATL/Data-Science-for-Scientists-ATL.github.io gh-pages:master
In the last line above, you are using git to push to your separate repository, specifically you're pushing the contents of the gh-pages branch of your source repository to the master branch of your Username.github.io repository. That's why at the end of the line you write gh-pages:master. Explaining the concept of git branches is beyond the scope of what I feel like writing right now :) but you can read about it in the "helpful links" section at the end of this post.
if pushing fails, e.g. because you already have content in the repository, you can force it with the -f flag. Be warned that this will overwrite everything:
(pelican-blog) $ git push -f https://github.com/Data-Science-for-Scientists-ATL/Data-Science-for-Scientists-ATL.github.io gh-pages:master
Stylin'
Contributors to Pelican have developed many themes: http://pelicanthemes.com/
One thing I didn't address much in my demo was how to use them.
A description of my opinionated method follows; for a less partisan take, you can read the docs.
I always find the use of themes confusing in Pelican. It comes with a tool for managing them, pelican-themes, that basically copies them to your computer. You then change the settings of your project to use a certain theme, but the files belonging to the theme are not of any one project.
I have a feeling that almost everyone modifies themes to some extent, so what would seem more natural to me would be a tool that would copy the files of one individual theme into your project, in a themes subdirectory, so that you could then go ahead and modify it.
But currently there's no built-in tool to do that, as I remembered after staring at the docs, so I did what some other part of the docs suggests instead, which was "create" one by modify an extant theme. Because all the Pelican themes are in one repository, you will have to copy all of them to some other place on your computer, and then copy one of the themes from that place to your project folder.
I went with pelican-bootstrap3 because it has a lot of bells and whistles. I based my decision to use pelican-bootstrap3 in part on this handy blog post from Christine Doig that explains in detail how she modified her theme. Lots of good ideas there:
https://chdoig.github.io/create-pelican-blog.html
If you also use pelican-bootstrap3, I very much recommmend actually reading the README.md
In particular note that you need to add the following lines to your pelicanconf.py file:
PLUGIN_PATHS = ['path/to/plugins', ]
PLUGINS = ['i18n_subsites', ]
JINJA_ENVIRONMENT = {
'extensions': ['jinja2.ext.i18n'],
}
If you don't do this, you will get a very helpful error message:
CRITICAL : undefinedError :'_' is undefined.
(Apparently, I am not the first person to experience this: https://github.com/getpelican/pelican-themes/issues/482)
Summary
Okay, now you've read a blog post about the meeting of our data science group yesterday about how you set up a your own data science blog, based on a bunch of data science blogs! Now you can set up your own blog and blog about data science blogging! Please let us know when your book comes out and look for much less meta posts from the future, unless this is the only post we ever write.
Helpful links + more reading
[1] get Anaconda here, with the conda command-line tool for managing packages and installing libraries (including many scientific libraries): https://www.anaconda.com/download/1. Here is my first footnote. ↩
[2] good example of why you would use virtual environments: https://www.dabapps.com/blog/introduction-to-pip-and-virtualenv-python/ ↩
[3]all about Markdown: https://daringfireball.net/projects/markdown/ ↩
[4] using ghp-import to publish to Github (from Pelican docs): http://docs.getpelican.com/en/stable/tips.html#publishing-to-github ↩
[5] branching: what is it? https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell ↩